
インテリジェント・ストレージのアーキテクチャー最適化技術
Storage Magazine 2020年11月号より
Dan Sullivan
インテリジェント・ストレージ・アーキテクチャーの最も優れた最適化技術と、そのシステムがあなたの会社のデータ資産から、どのようにストレージのパフォーマンス/使用効率を改善するのかを、詳細に見ていこう。
力ずくで物事を解決するやり方は、ストレージの歴史のほとんどの時期において、その技術を進歩させる重要な役割を果たしてきた。ストレージ機器をより大きく、より速く、より高密度にすることは、これまでうまくいったし、今後もそれがストレージ・システムを改善することに疑う余地はないと思われた。しかし、もはやこれはストレージのコストとパフォーマンスを改善する最善の方法ではなくなった。それに代わって、インテリジェント・ストレージ・システムの形態の機械学習と分析が、今やストレージ技術の最も重要な進歩を推進するものになった。
インテリジェント・ストレージ・システムとは何か?
インテリジェント・ストレージ以前のシステムは、SSDからの読み込み、ネットワーク・インターフェースへのパケット送信などの下位レベルの処理を最適化していた。インテリジェント・ストレージ・システムは、デバイス内のパフォーマンスを改善するためにデバイス処理のデータを使用し、システムレベルの処理を最適化するために、データ仕様のパターンを観察することによって、抽象化したより上位のレベルで処理を行う。
インテリジェンスは以下の三つの異なるレベルでストレージ・システムに組み込まれる。
- デバイス・レベルの最適化
- ティアード・ストレージとデータライフサイクル管理
- データ・アクセシビリティ
である。
デバイス・レベルの最適化の場合、機械学習のアルゴリズムが、アクセス・パターンの相似からデータのカテゴリを割り出す。機械学習モデルが、将来一連のブロックがリードされそうだと予測したならば、これらのブロックは実際のリードの前にキャッシュにコピーされる。
これによってリードのレイテンシが低減されるが、巨大なデータ量のみならずGPUや他のアクセラレーターの処理速度に合わせて十分なデータを供給することが要求される機械学習モデルのトレーニングにとっては、この事は特に重要である。
ティアード・ストレージとデータライフサイクル管理機能は、デバイス・レベルの最適化機能よりも大きな量のデータに重点を置いている。後者が、すぐ使われるデータの最適な配置を目的とし、潜在的なエラーを監視するのに対して、前者は長期間保存するデータの配置の最適化のために設計されている。例えば、最近生成された時系列データは、より古い時系列のデータよりもクエリされる可能性が高い。ティアード・ストレージ・インテリジェンスは、異なるアクセス・パターンを検知できるので、アクセスされそうなデータは低レイテンシだが高価なストレージに配置し、古いデータはより安価なストレージ・プラットフォームへと移動する。
データの量と種類が増えるにつれて、特定のデータを見つけることはますます難しくなってくる。確かに、特定のファイルを名前で検索したり、特定の時間に作成された一連のアーカイブ・ファイルを戻したりするだけならば、簡単なオペレーションで済む。しかし、全てのアクセス要求がそのような単純なものとは限らない。例えば、技術者たちは本番環境でのインテリジェント機械学習モデルのパフォーマンスをお粗末だと思うかも知れない。これは、機械学習モデルが十分に広範なトレーニングセットでトレーニングされていないからだ。
彼らが求めているのは、データをその特性によって探すストレージ・システムかも知れない。インテリジェント・インデクシング、タギング、リトリーバルは、このようなユースケースを実装する上で重要な機能だ
インテリジェント・ストレージ・システムの機能
インテリジェンスは生物の中では様々な方法で進化を遂げる。インテリジェント・ストレージ・システムにも、同様のアプローチが見られる。インテリジェント・ストレージ・システムで使われている最も一般的な機能のいくつかを以下に挙げる。
- 予測分析
- 分散ストレージおよび分散処理
- データ配置最適化
- 拡張セキュリティ
一部のインテリジェント・システムでは予測分析手法が使われている。これらの根幹となっているのは、統計的かつ機械学習による方法だ。この方法によってシステムは、デバイスの処理データのパターンを検知し、それらのパターンを使って、デバイス上に保存されているデータがどのようにアクセスされるかを予測する。
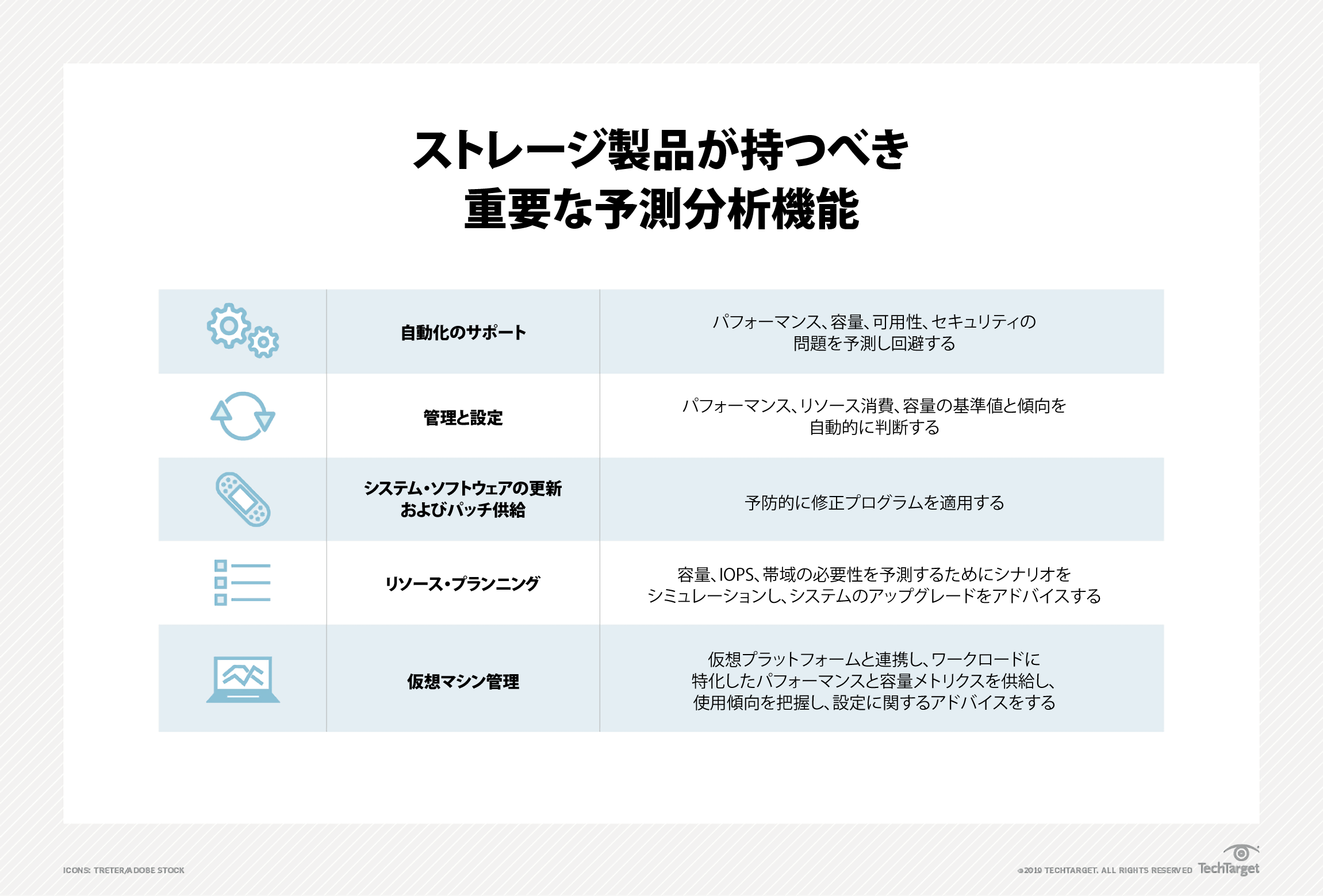
デバイス・レベルの最適化では、この種の分析はデバイスの一つ一つの処理を記録したI/O履歴ログを頼ることになる。統計に基づいた手法では、ユーザーにとって当該データが何を意味するかを理解する必要がない。セールス・トランザクションによって作られたデータだろうが、車両センサーによって生成されたデータだろうが、何の違いもない。大事なのは、それがどこにあるのか、またいつ書かれたか、といったデータの特性だ。一般に、この種の予測分析ではクラスタリング・アルゴリズム*訳注1が使われる。
訳注1:特性が共通するデータを「クラスタ」と呼ばれるグループに分割する処理のこと。
インテリジェント・ストレージ・システムは、複数の機器にまたがって使える。IoTセンサーは、保存とその後の分析のためにデータをエッジ・デバイスに送ることができる。エッジ・デバイスは、どのデータをローカルに保存し、どのデータをセンターの分析システムに送るべきかを判断するための事前分析を実行できる。例えば、センサーからの一連の変則的測定値は、即座に対処すべき何らかの問題を示しているのかも知れない。このデータは、インジェスチョン(データ収集)処理の次の段階に直接送られ、それ以外のデータは単に保存され、後でまとめて送られる。

インテリジェント・システムは、異なるストレージ・ティア間のデータを管理することもできる。最近の時系列データは古いデータよりもクエリされる可能性がはるかに高いため、低レイテンシのストレージに保存されるべきだ。一方古いデータは、レイテンシは高いかも知れないがコストは低い、低位のティアに移動可能だ。この種のデータライフサイクル管理は自動化しておく必要がある。この手の管理が要求するデータの量と種類は、手動による管理に全くなじまないからだ。人間ができるのは、せいぜい高レベルのライフサイクル管理ポリシーの定義くらいだ。そのポリシーを広範なデータセットとユースケース間に実装するのは、インテリジェント・ストレージ・システムに任せればいいのだ。
拡張セキュリティは、インテリジェント・ストレージのもう一つの機能だ。アプリケーションとサービスは、CPU使用、IOPS、その他一般的な監視メトリクスについて、予測可能なパターンを持っていることが多い。基準となるオペレーションからの逸脱は、潜在的なセキュリティ問題を示していることもあるが、別に珍しいことではないので、ユーザーは潜在的な障害やセキュリティ違反、その他オペレーションの脅威を示している逸脱を検知できるように、インテリジェント・ストレージ・システムを調整する必要があるだろう。例えば機械学習の技術者は、制御可能な環境下で生成された、ランサムウェア攻撃のパフォーマンス・データを収集して、実際に攻撃が開始された時、それを予測するモデルを開発することができる。
これらの機能は、前述した通りデータ配置の最適化のように、タスクごとに分かれている。しかし実際のところ、企業は広範な基盤コンポーネントにこれらの機能を実装する。それゆえに、インテリジェント・ストレージ・システムのアーキテクチャー全体を理解しておくことが重要である。
インテリジェント・ストレージ・システムのアーキテクチャー
ストレージ・システムは、インテリジェント機能を備えたものも含め、サーバー、ネットワーク、ストレージ・システム自身をも包含する、より大きな基盤の一部である。インテリジェント・ストレージ・システムは、4つの主要なコンポーネントを持っている。
- フロントエンド
- キャッシュ
- バックエンド
- 永続ストア(ディスク、SSDなど)

フロントエンドの主要な役割は、ストレージ・システム・ネットワークと通信することだ。フロントエンドは、ポートとコントローラで構成されている。フロントエンド・ポートは、ホストサーバーがストレージ・システムに接続することを可能にする。ポートは、SCSIやファイバチャネルなどのトランスポート・プロトコルをサポートするように設計されている。フロントエンド・コントローラは、キャッシュに出入りするデータの経路を制御する役割を負っている。I/O処理の最適化の役割も、このコンポーネントが担っている。最適化は一般的に、I/Oコマンドが実行される順番を最適化するコマンドキューイング・アルゴリズムを使って行われる。
キャッシュは、I/O処理実行に必要な時間を削減するために使われる、低レイテンシのメモリだ。その時間とは、少なくともストレージ・システムを使っているアプリケーションやサービスから見た時間だ。キャッシュは、データ自身とデータのロケーション情報の両方をキャッシュとディスクに保存する。
I/O処理のどの点を最適化すべきかによって、キャッシュ内のデータ管理に用いられる戦略は変わってくる。例えば、ライトバック・キャッシュではデータがキャッシュに書きこまれ、肯定応答(acknowledgment)がアプリケーションに送られる。肯定応答が送られた後に、データがディスクに書き込まれる。この方法によって、アプリケーションが肯定応答を待つ時間は最小化されるが、万が一ディスクにデータが書き込まれる前にキャッシュに障害が起きればデータが失われる危険をはらんでいる。ライトスルー方式では、データはキャッシュに書かれた直後にディスクに書き込まれる。これによって、データ損失の危険性は低減するが、レイテンシが増加するという代償を払わなければならない。

バックエンドは、キャッシュとHDDやSSDのような永続的ストレージとのインターフェースだ。フロントエンドと同じように、バックエンドもポートとコントローラから構成されている。ディスクはポートに接続され、コントローラがディスクへのリード・ライトの処理を管理する。バックエンドのインテリジェンスには、エラー検知と訂正機能が入っている。
ストレージ・システム内での処理最適化にとってのインテリジェンスは重要だが、ストレージと計算処理全体を最適化するには、設置されているストレージを、ストレージ基盤の様々な技術、それぞれの特徴を踏まえて考えなければならない。現在、そこにはオンプレミス基盤とクラウド基盤が含まれる。
ハイブリッドクラウド基盤におけるインテリジェント・ストレージ
将来、ストレージ管理に対するインテリジェンスの最も優れた使い方になりそうなのは、それがアプリケーションおよびハイブリッドクラウド基盤を横断するワークロードの最適化に適用される場合だろう。
アプリケーションは構造化データを管理するため、データベースに大きく依存している。データアウェア・デバイスは、アプリケーション・レベルの処理に関するデータを使って、これらのデータベースのストレージパフォーマンスを改善出来る。例えばデータアウェア・デバイスは、データベース管理システムによって生成されたデータを使って将来必要になるデータを予測することが出来る。しかし、アプリケーションとデータベースが他のシステムから切り離して使われることはまれだ。むしろ、これらはより大きなワークフローの一部となっていることが多い。

ストレージ・インテリジェンスの最上位の機能は、ワークロードを監視し、コンピュート、ネットワーク、ストレージ機器から集めた情報を使って、複数のストレージ機器を横断してストレージの最適化を行うことだ。このレベルのインテリジェンスは、クラウドストレージのコストを抑制するのに役立つ。クラウドストレージのコストは管理が難しく、使用量が予期せぬ金額になることが頻繁にある。
ストレージのパフォーマンスとコスト効率を改善する事は、もはやハードウェアの改善で済む話ではなくなった。現在の最も重要な進歩の原動力となっているのは、単一機器内の低位のI/O処理からハイブリッドクラウド基盤上のワークロード監視とデータ配置の最適化までをカバーする、インテリジェント・ソフトウェアである。貴社のストレージ基盤はどれ程インテリジェントだろうか?
著者略歴:Dan Sullivan(理学修士)は、IT業界で20年以上の経験を持つ著者、システムアーキテクト、コンサルタント。先進解析、システムアーキテクチャー、データベース設計、エンタープライズ・セキュリティ、ビジネス・インテリジェンスに造詣が深い。

Copyright 2000 - 2021, TechTarget. All Rights Reserved, *この翻訳記事の翻訳著作権は JDSF が所有しています。
このページに掲載されている記事・写真・図表などの無断転載を禁じます。
 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム JEITA連載寄稿
JEITA連載寄稿 「Storage Magazine」
「Storage Magazine」
