
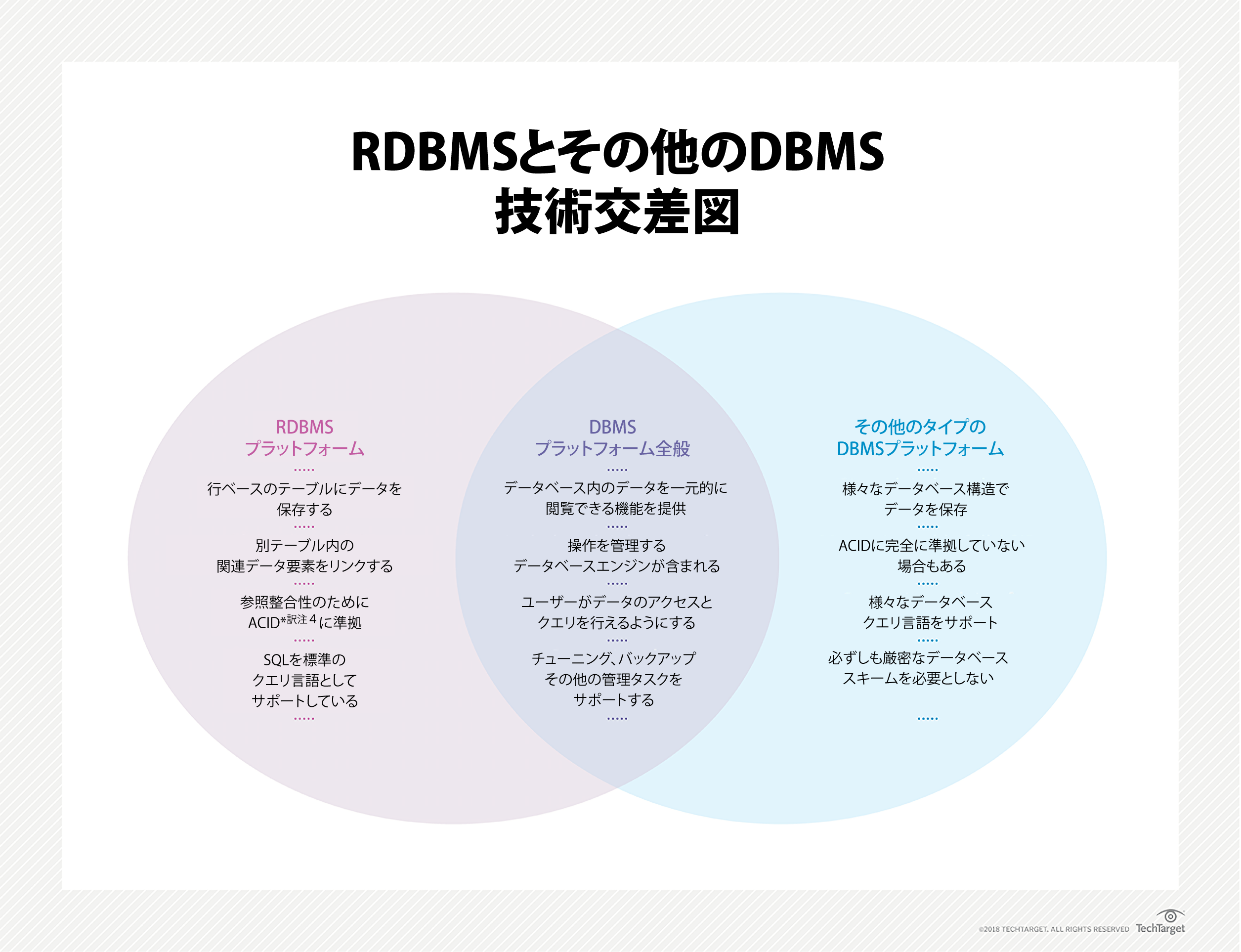
構造化と非構造化データストレージの境界線が消えていく
Storage Magazine 2020年11月号より
Dun Sullivan
低コストの非構造化オブジェクト・データストレージでは、Prestoのようなオープンソース・ツールがデータの永続性を保ち、そこでの情報アクセスは依然としてSQLのような構造化データアクセス・ツールで行われている。
その昔、企業は構造化データをリレーショナル(あるいは、時としてNoSQL)データベースに保存し、非構造化データをAmazon S3やGoogle Cloud Storageのようなオブジェクト・ストレージシステムに保存した。しかし、構造化データストレージと非構造化データストレージの区別がはっきりしなくなってきたために、企業の構造化データ保存、クエリ、管理に大きな影響が出て来ている。
この変化の理由は、Prestoのようなプラットフォームの登場である。無料かつオープンソースのクエリ・エンジンのPrestoやその仲間は、データの永続性を保つために低コストのオブジェクトストレージを使えるようにしながら、そこでの情報アクセスは依然としてSQLのような構造化データアクセス・ツールで行っている。
それでは、販売、在庫、フルフィルメント*訳注1管理システムのような、いくつものオンライン・トランザクション処理システムから流入してくるデータでいっぱいになっている一般的なデータウェアハウスを詳細に見て行こう。
訳注1:フルフィルメントは、通信販売やECにおいて、受注から配送までの業務(発注、問い合わせ、梱包、発送、配送、仕入れ、納品、検品、在庫管理、返品処理、クレーム対応、コールセンター、入金管理、代金回収、返金処理など)の一連のプロセス全体のことを指す。
一般的なデータウェアハウス
データは、前述のシステムから一定の間隔で抽出される。次に、データウェアハウスで使えるように、変換され再度構造化される。変換されたデータは、データウェアハウスに直接書きこまれる場合もあるし、オブジェクト・ストレージシステムにファイルとして保持される場合もある。後者の場合、データは一般的にロードプロセスでデータウェアハウスにコピーされる。
後者のシナリオでは、データウェアハウスはAmazon RedshiftあるいはGoogle Cloud BigQueryのようなプラットフォーム上で稼働している。どちらのプラットフォームもマネージド・サービスだが、Redshiftの場合、サーバーの大きさやその他の管理方法を決めなければならない。これらのサービスの、長所と短所を比較する必要もあるだろう。
- これらのサービスを使う長期的なメリットは、ユーザーがSQLやビジネス・インテリジェンス・レポーティングツールを使って、データをクエリ、レポート、可視化できるようになる点だ。
- データウェアハウスを管理する上での短所は、コストだ。これは、基盤についても管理オーバーヘッドについても同じことが言える。
Redshiftなどが稼働しているデータウェアハウスで、データをブロックストレージに保存して使われることがあるが、それはオブジェクトストレージよりも高価である。
PrestoとAmazon Athenaはどのように使われるか
しかし、ETLプロセス(抽出、変換、ロード)の最後の手順を無くすことができたらどうだろうか?変換したデータをリレーショナルまたはアナリティカル・データベースにロードする代わりに、オブジェクトストレージに保存したデータを、データベース管理システム(DBMS)にあるデータと同じように操作できるとしたら? それができれば、オブジェクトストレージのコストメリットと、データベースをクエリするアクセス性が手に入る。

ここで登場するのがPrestoと、PrestoをベースにしているAmazon Athenaだ。これらのプラットフォームは、オブジェクトストレージに保存されているかも知れないデータに対しても、SQLのインターフェースを提供する。企業がParquet and ORCのようなカラムナフォーマット*訳注2のファイルにデータを保存した場合、カラムナフォーマットでデータを保存したデータベースのいくつかの長所を享受できる。Prestoはカラム型クエリ・エンジンなので、列データを読むときにパフォーマンスを最適化できる。特に、行ベースのファイルフォーマットに比べ、より優れたクエリパフォーマンスと小さなフットプリントを提供する。
Prestoやファイルのダイレクトクエリが出来るその他のプラットフォーム、およびDBMSを使うときは、その相違点に注意することが重要だ。
- データベースは、増分更新、挿入、削除用に設計されている。このことは、リアルタイムまたは準リアルタイムでの更新を必要とする分析アプリケーションを使う際に重要になる。
- オブジェクトストレージでのファイルのクエリは、バルク・アップロードが許可されていると効率が良い。また、完全性制約*訳注3のようなリレーショナルDBMSの機能の多くは、ファイルベースのストレージを直接扱う場合は使用できない。
カラムナ・ファイルフォーマットは行ベースのフォーマットに比べてパフォーマンスを向上できるものの、DBMSはさらに良いパフォーマンスを提供する。大量のデータを低レイテンシでサポートする必要があるのならば、リレーショナルまたはアナリティカル・データベースが最良の選択だ。
Prestoのようなファイルを直接クエリするプラットフォームの持つ最大のメリットは、簡潔さだ。特に、構造化と非構造化データストレージ、および管理に対して明確な境界線を作らないところが、ユーザーには有利に働く。Amazon Athenaのようなマネージド・サービスを使う時は特にそうだ。
訳注2:カラムナフォーマットは、列指向フォーマットとも呼ばれ、列方向に連続してデータを格納する方式。列単位でデータを取り出す分析用途に向いている。
訳注3:完全性制約とは、データの完全性を維持するために用いられるルール・セット。
訳注4:ACIDは、トランザクション処理の信頼性を保証するための4つの特性、“Atomicity”(原子性)、“Consistency” (一貫性)、“Isolation”(独立性)、“Durability”(耐久性)を表す。
価格体系の単純化が好影響
少なくともGoogle Cloudでは、ベーシックストレージの価格がまとまりつつあり、より単純になってきている。例えば、Googleがペタバイト規模のデータウェアハウス用に設計したマネージド・分析データベースのBigQueryは、Google Cloud Storageの価格をそっくりそのまま反映した価格表を採用した。
BigQuery内のアクティブデータ、即ち過去90日以内に更新があったデータには、1ヶ月にギガバイトあたり$0.02が課金され、インアクティブデータには、1ヶ月にギガバイトあたり$0.01が課金される。Google Cloud Storageの1ヶ月あたりのギガバイト単価は$0.02、Nearline の1ヶ月あたりのギガバイト単価は$0.01である。
他のクラウドベンダーが同様の価格戦略を取れば、構造化と非構造化データストレージの境界線はさらに薄れていくだろう。
著者略歴:Dan Sullivan(理学修士)は、IT業界で20年以上の経験を持つ著者、システムアーキテクト、コンサルタント。先進解析、システムアーキテクチャー、データベース設計、エンタープライズ・セキュリティ、ビジネス・インテリジェンスに造詣が深い。

Copyright 2000 - 2020, TechTarget. All Rights Reserved, *この翻訳記事の翻訳著作権は JDSF が所有しています。
このページに掲載されている記事・写真・図表などの無断転載を禁じます。
 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム JEITA連載寄稿
JEITA連載寄稿 「Storage Magazine」
「Storage Magazine」
