
これからのAIストレージからフラッシュを外す理由
AIアーキテクチャーとそのワークロードによる絶え間ない容量増加要求と課題を解決するのは、ノード数の多いハードディスクのみで構成されたスケールアウト・ストレージだ。その理由を見て行こう。
Storage Magazine 2月号より
Nick Cavalancia
今後数年の間に、多くの企業がAIに投資するだろう。これらの投資は、少なくともITの運用に充てられることになり、ITがデータセンター内のシステムで常時生成される大量のテレメトリデータを処理するためにAIを使うだろう。そしておそらくほとんどの企業が、ビジネス向上を手助けしてくれるAIアプリケーションに投資することになりそうだ。
その際、プロジェクトの成功への鍵を握っているのは、これらのAI構想を支えるストレージ基盤だ。企業が自社のAIワークロードを支えるのに最適なAIストレージをデプロイしなければ、これらの投資はお金をドブに捨てるだけのことになるだろう。
ストレージがAIにとって重要なわけ
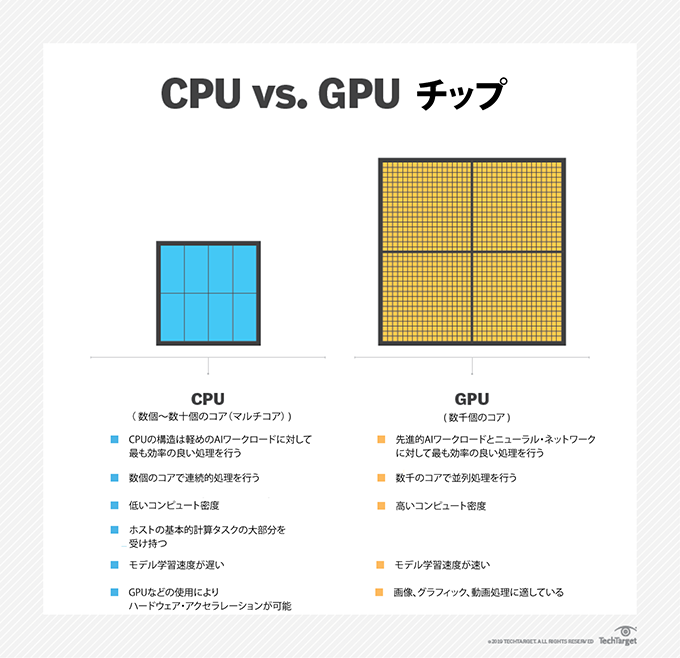
ほとんどのAIワークロードが、大量の情報を処理することによって「インテリジェント」になっており、これから管理する環境の振る舞いを学習することができる。AIアーキテクチャーは、従来の設計に合わせる傾向が強い。大半がコンピューター・ノードのクラスターで、一部または全部のノードにGPUがついている。各GPUは最大でCPU100個分のパフォーマンスを提供するが、一般に売られているCPUよりも高価だ。
AIストレージ・アーキテクチャーの最も重要な課題は、GPUに常にデータを与え、決してアイドル状態にしないことだ。一般的に、GPUが処理するデータ数は、数十億とまではいかなくても数百万はあり、その中身は多くの場合、センサーやIoT機器によって生成される、比較的小さなファイルである。その結果、AIのワークロードは、シーケンシャル・リードとランダム・リードが混在したI/Oパターンになることが多い。
もうひとつの課題は、ストレージの要件だ。AIがより高度に(より賢く)なるためには、データをどんどん処理する必要がある。ここでの大容量ストレージ要求とは、100TBでスタートしたAIプロジェクトが、わずか数年で100PBの規模になることを意味している。300PBから400PBくらいのAI容量は、ますます一般的になりつつある。
初期の段階では、多くのAIプロジェクトがオールフラッシュ・アレイに頼っていた。高価なGPUを働かせ続けるのに必要なパフォーマンスを提供するためだ。今日(こんにち)多くのAIプロジェクトが、ネットワーク越しであっても高いパフォーマンスを提供するNVMe-oFシステムの高パフォーマンスと低レイテンシをフルに利用している。これらの環境の規模が拡大し、高度な自律運用を試みる時に必要になるのは、さらなるコンピュートおよびGPUリソースと相当な量のストレージ空間だ。
次世代のAIストレージ基盤は、さらに高度な自律運用が要求する容量を満たすために、規模を拡大する必要がある。また、スケールアウト・コンピュート・クラスターが要求するパフォーマンスに合わせて、レベルアップもしなければならない。企業が自社のAIワークロードの規模を拡大し、IT部門がそのクラスターにGPUを搭載したノードを増設すると、I/Oパターンはさらに並列的になる。
スケールアウトAIストレージ
スケールアウト・ストレージ・アーキテクチャーは、次世代のAIワークロードが作りだす容量の課題を解決してくれる。さらに、ストレージ・クラスター内の特定のストレージ・ノードへの直接アクセスを可能にする機能を持っている、スケールアウト・ストレージ・アーキテクチャーであれば、先進的AIワークロードの並列I/O要求を満たすことができる。とはいえ、並列アクセスではストレージ・クラスターがボトルネックにならないように複数のノードでアクセス管理を行う、新しいタイプのファイルシステムが必要になる。
大半のAIワークロードが、数百とまでは行かずとも、数十PBの容量を必要とする以上、ストレージ・プランナーがAIストレージ・アーキテクチャー内のストレージ・ティアにオールフラッシュだけを使い続けるというのは、ありそうにない。フラッシュの価格は大幅に下がってきたとはいえ、大容量HDDは依然としてはるかに安価だ。現在のAIアーキテクチャーは(少なくとも今のところ)フラッシュとディスクの両方を管理し、双方のティア間で透過的にデータを移動させる必要がある。しかし、これらのティアの管理は自動化しなければならない。
一部のケースでは、ワークロードのデータセットの規模を考慮して、大規模で多ノード、且つハードディスクだけのクラスターを構築した方が、ずっと良いかもしれない。と言うのは、これらのワークロードはあまりに巨大で、どんなキャッシュ・ティアであっても残らずあふれさせてしまうからだ。また、データのティアリングはストレージ・ソフトウェアのオーバーヘッドを招き、速度を低下させてしまう。多ノードでハードディスクだけを揃えたストレージ・クラスターは、GPUが処理する速度に合わせてデータを供給し続けるのに十分な、並列パフォーマンスを提供してくれることだろう。
AIはHPCレベルのストレージを要求する
AIワークロードが成熟するにつれて、AIストレージ基盤は、従来のエンタープライズ・ストレージよりもむしろハイパフォーマンス・コンピューティング(HPC)ストレージ・システムに似てくるだろう。これらの基盤は、ほぼ確実にスケールアウト設計で、巨大な容量要求のためにHDDと、ワークロードの性質によっては、テープが使われる可能性もあるだろう。
その一方、フラッシュはコストが高すぎること、およびAIと機械学習がその容量をすぐ使い果たしてしまうこと故に、これらのシステムのストレージ媒体としては、すぐに役に立たなくなるかも知れない。少なくとも、フラッシュがAIストレージ・アーキテクチャーの中で果たす役割は小さくなるだろう。今後これらの環境は、RAM、ハードディスク、テープの組み合わせへと移行していくからだ。
著者略歴:George Crump は、ストレージと仮想化を専門とするIT アナリスト企業Storage Switzerland の社長である。

Copyright 2000 - 2020, TechTarget. All Rights Reserved, *この翻訳記事の翻訳著作権は JDSF が所有しています。
このページに掲載されている記事・写真・図表などの無断転載を禁じます。
 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム JEITA連載寄稿
JEITA連載寄稿 「Storage Magazine」
「Storage Magazine」
