
データ解析用機械学習でビッグデータのストレージ問題を解決する
Storage Magazine 8月号より
著者:Brien Posey
大手ベンダーとラムダアーキテクチャー、FPGA、コンテナといった技術によってサポートされたAIと機械学習が、ビッグデータ解析における問題をいかに解決しているかを理解しよう。
業種の違いを越えて大企業は、既存データに隠れた価値を発見してきた。データの中に隠れた本質を見抜くために機械学習のアルゴリズムを用いることは、またたく間に常識となった。しかし、多くのメリットがある反面、データ解析用機械学習はいくつかの課題を抱えている。特に問題なのは、ストレージ基盤に関するところだ。
データには隠れた価値が含まれているので、企業はなかなか古くなったデータを削除しない傾向がある。それによって、ストレージは加速度的に消費され、ストレージ容量計画は複雑になる。さらに、実際の分析プロセスでは下層のストレージ基盤に新たな負荷が発生する。
いささか皮肉ではあるが、ベンダー数社はビッグデータ解析が作り出す問題を解決するツールとしてAIを使い始めた。実際のところ、これらのベンダーは解析を試みる際に単一の技術をベースにするのではなく、異なる技術を集めたものを使っている。
ラムダアーキテクチャー
ワークロード・プロファイリングやキャパシティ・プランニングのようなものにAIを使う際には、現在のストレージの使用状況と正常性のデータにアクセスできることが重要だ。とはいえ、リアルタイムのデータにだけ頼るのも望ましいとは言えない。
リアルタイムのストリーミングデータを使用する際の問題は、データが生(ナマ)のままで一切整理や要約がされていないところだ。データストリームに欠落が存在するかもしれないし、データがリアルタイムで使われているために、処理できる量が大幅に制限される。
比較的現在に近いデータ(但し、リアルタイムではない)を使う方が、データ解析用機械学習でより多くの情報を得られる場合が多い。しかしこのデータは、今この場を流れているリアルタイムデータほど最新ではない。
ラムダアーキテクチャーは、二つの異なるレイヤー(バッチレイヤーとスピードレイヤー(訳注:スピードレイヤーはリアルタイム処理結果を提供する層))に同時にデータをストリーミングすることによって、この問題を解決する。バッチレイヤーの仕事は、単純にデータを貯めることだ。このデータは、リアルタイムで更新されていないので、データの質を上げるためのバッチルールが使える。一部のモデルではバッチレイヤーは、データをクエリ・キューに答えるバッチビューを生成する第三のレイヤー(サービスレイヤー)でも使えるようにしている。
インバウンドのデータも、スピードレイヤーにストリーミングされ、リアルタイムのデータビュー機能を提供する。
ラムダアーキテクチャーに対してクエリがなされると、企業はバッチビューとリアルタイム(スピード)ビューの二つを統合した解析結果を得ることができる。これにより、ラムダデータは他の方法で得るよりも、より包括的で完璧なデータイメージの提供が可能になる。
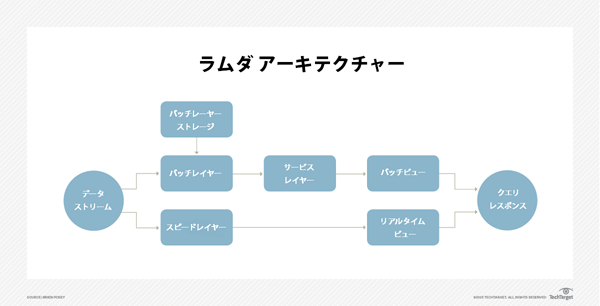
ラムダアーキテクチャーを動かすためには、レイテンシは非常に低く、またインバウンドのデータストリームを受け入れられるだけの十分な拡張性がなければならない。このようにラムダアーキテクチャーは、例えばハイパーコンバージドを含む複数ノード間でのスケールアウトを前提に設計されている。このスケールアウト・アーキテクチャーによって、システムはハードウェア障害に対するフォールトトレラント機能も備えている。
カスタムFPGA
カスタムFPGA(Custom Field-Programmable Gate Arrays)はITの世界では比較的新顔だが、電子工学の分野では長年にわたって使われてきた。それはそれとして、ITの世界ではハードウェアベンダーが、データ解析用機械学習製品の中のCPUやGPUの代替品として使い始めている。実際、Intelは2015年にFPGAメーカーのAlteraを買収するのに1670万ドルを投じている。
歴史的に、FPGAはコストと電子機器を設計する複雑さを低減するために使われてきた。現在の電子機器は、ほとんどいつも集積回路(IC : Integrated Circuit)をベースにしてきた。これは、電気工学で新しい機器を設計するときは、その機器のニーズを満たすICを探し出すか、カスタムICを作るしかないことを意味する。ただし、後者は高価で複雑な処理になる。
電子工学においては、FPGAがあるのでカスタムICを作成する必要はない。他のタイプのICと違って、FPGAは一つ一つがプログラム可能だ。これは、電子工学でFPGAを特注のICと同じような動きをするように構成できるということだ。
機械学習にとってFPGAが魅力的なのは、FPGAがカスタムICのように動く機能があることだけにとどまらない。FPGAには他に考慮すべき二つの特徴がある。
■極小レイテンシの実現
これは、CPUのような汎用機器が動作するよりも、特注で専用機器として動作する FPGAの機能によるところが大きい。さらにFPGAは、WindowsやLinuxのような汎用OSを稼働させるという重荷を背負っていない。FPGAが時として1マイクロ秒もの低レイテンシを実現できるが故に、AI機械学習のプラットフォームの中で使うのに非常に適している。
■浮動小数点演算機能
機能があるとはいえ、FPGAには今日(こんにち)のCPUやGPU程のスピードや精度が不足しているため、現世代のFPGAはAIトレーニングには向いていない。とはいえ、FPGAは推論作業においては抜群の力を発揮する。異なるプラットフォーム上で初期のトレーニングデータが生成され、FPGA内蔵のストレージにコピーされさえすれば、ストレージベンダーはFPGAを、機械学習機能をストレージ・ハードウェアに統合するためのプラットフォームとして使用できるということだ。
トレーニング vs. 推論
より抽象的に言うと、機械学習はトレーニングと推論の考え方に基づいている、と言える。トレーニングとは、まさに日常で使われている意味でのトレーニングだ。すなわち、機械学習のプラットフォームにどのように特定のタスクを実行するかを教え込む処理である。トレーニング処理の代表例は、猫を認識するためにコンピューター・アルゴリズムが訓練された、2012年の実験である。この実験によって、トレーニング処理におけるCPUとデータがいかに集中的に使われるかが明らかになった。猫を認識する学習には、1万6千台のコンピューターが共同で、1千万枚の猫の画像を解析する必要があった。その結果出来上がったのは、1枚の画像の中に猫がいるかいないかを認識できるアルゴリズムだった。
機械学習のもう一つの主要なコンポーネントは推論だ。これは、機械学習のアルゴリズムがトレーニング処理を終了した後に実行するタスクを指す。前述の猫認識アルゴリズムの例でいうと、アルゴリズムがこれまで見たことがない画像を見たとき、推論が実行され、過去のトレーニングに基づいて、画像が猫を含んでいるか否かを正しく判断する。
計算処理としては、推論はトレーニングと大きく異なっている。トレーニング処理がCPUに極めて大きな負荷をかけ、且つ通常膨大な量のデータ解析を必要とするのに対して、推論は単に、トレーニング処理のときに蓄積した知識をベースにしている。そのため、推論はトレーニングより、はるかに素早く実行され、費やされる労力も大幅に小さい。
コンテナ化ストレージ
コンテナは、ビジネスアプリケーションを稼働させるためのプラットフォームとしてよく知られているが、機械学習においても力を発揮する可能性を持っている。
機械学習アルゴリズムをトレーニングする際には、計算処理が集中する傾向がある。しかし、一旦トレーニングが終われば、企業は大したCPUリソースを必要とせずにこれらのアルゴリズムを使える場合が多い。トレーニング処理後の機械学習の処理は、比較的負荷が軽いため、これらの処理をコンテナ内で走らせるケースが増えてきた。最もよくコンテナ化される機械学習の技術の一例は、TensorFlowである。
TensorFlowは、機械学習を容易にするためにGoogleが設計した、オープンソースのPythonライブラリーだ。Googleは、Tensor Processing Unitという自製のカスタムICを作成した。このICは、Tensorの使用を前提に設計された。Googleは、このTensorFlowがコンテナを含む、ほぼ全てのプラットフォームで動作するように設計した。
TensorFlowのコンテナ化の最も魅力的な理由のひとつは、アプリケーションが大きな規模で稼働できるところだ。企業は、計算グラフをTensorFlowクラスターに分散して、さらにこれらのクラスターを構成するサーバーをコンテナ化できる。
ベンダーサポート
データ解析用機械学習機能を組み込んだ最初のストレージ製品の一つは、Dell EMC PowerMaxファミリーである。Dell EMCはPowerMaxを世界最速のストレージアレイとして宣伝した。この製品は、最大1千万IOPSを提供し、150GBpsの帯域を実現したからである。
PowerMaxの目覚ましいパフォーマンスを、(最低でも部分的に)支えているのは機械学習である。同製品に組み込まれた機械学習エンジンは、データの要求予測に基づいてデータを最適なメディアタイプ(フラッシュまたはストレージクラス・メモリ)に配置する予測解析を自動的に使用してパフォーマンスを最大化している。
ストレージをよりインテリジェントにするために機械学習を使っているベンダーは、Dell EMCだけではない。Hewlett Packard Enterprise (HPE)はハイブリッドクラウドにインテリジェンスを与えるために、データ解析用機械学習を使っている。
一般的にハイブリッドクラウドには、企業が所有するデータセンター内のストレージと、複数のパブリッククラウド内のストレージが含まれている。データがどのように使われ、どこに保存されているかを調査し、効率が悪いところを見つけ出すのは、従来IT部門の役目だった。HPEのIntelligent Storage技術は、潜在的要求を理解するためにワークロードを解析し、ストレージコスト、パフォーマンス、データが使われる場所への近さ、使用可能容量などの基準に基づいてデータを最適な場所に再配置する。Intelligent Storageは、リアルタイムでの条件変更や必要に応じてデータを再配置する機能も持っている。
次に実現したいことは?
ストレージ用機械学習の力を利用したいと考える企業は、まず何を実現したいのかを決めるところから始めるべきだ。一度ニーズが特定されれば、直接要件に対応する製品を探すことができる。例えば、もしあなたの目標がパフォーマンスの最適化であれば、レイテンシを最小化し無駄なIOPSを無くすように自動的にデータを配置してくれる、データ解析ベースの機械学習製品を探したいと思うだろう。
特定されたニーズによっては、企業は必ずしも機械学習を活用したストレージ・ハードウェアを購入しなくても良いかもしれない。例えば自動で容量計画を行うタスクなどは、ことによると新規にストレージ・ハードウェアを購入しなくても、ソフトウェア・アプリケーションがやってくれるかも知れないのだ。
著者略歴:Brien PoseyはIT業界数十年の経験をもつMicrosoft MVP。前職は全国展開する病院・医療施設のCIO。

Copyright 2000 - 2019, TechTarget. All Rights Reserved, *この翻訳記事の翻訳著作権は JDSF が所有しています。
このページに掲載されている記事・写真・図表などの無断転載を禁じます。
 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム JEITA連載寄稿
JEITA連載寄稿 「Storage Magazine」
「Storage Magazine」
