

ストレージマガジン 5 月号より
Brien Posey
RPO(Recovery Point Objective:目標復旧地点)および目標復旧時間 (RTO: Recovery Time Objective)という考え方は、最近とみに陳腐化してきている。今日、世界が高度に相互接続されたことによって、ほとんどの企業はITレジリエンシー(障害からの回復力)を確保し、自社のリソースを常時利用できる状態にしておくことが当たり前と考えられるようになった。さらに重要なことには、ダウンタイムのコストは増加の一途をたどり、それは多くの企業にとって発生が許されないもの、かつ発生したらもはや損害額を背負いきれないものになってきている。
Ponemon Instituteが行った2016年の調査によると、データセンターのダウンタイムの全コストは、一時間あたり$740,357であり、2015年にクラウドバックアップ&DRaaSのInfrascaleが同様の調査を行った時より、若干高くなっている。今回の調査は、ダウンタイムがいかに高くつくかを示しており、ダウンタイムで失われる売上、従業員のコストなどを合わせると1分間あたり平均$8,851と算出している。
大企業にとって、損害額は途方もない額になることがある。2016年に起こったデルタ航空のシステム障害の損害額は、1億5千万ドルだった。
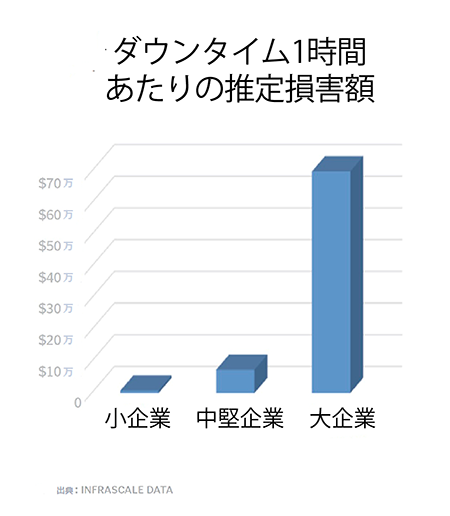
今回の調査はさらに、業務が回復するのにかかる時間は平均で18.5時間と述べている。ダウンタイムの1時間あたりの金額を掛けると、災害復旧のコストは膨大な額になる。それゆえ、IT業界が従来のバックアップ&リカバリー方式からDR方式またはBCP方式に方向性を転換しつつあるのも、至極当然の話だ。
リソースを常時利用できる状態にし、障害を回避するITレジリエンシーに重点を置くためには、これまでの仕組みをさらに拡張する必要がある。ここで重要になるのは、障害が起こりそうな箇所を見極めること、そしてそれに対するコンティンジェンシー・プラン(緊急時対応計画)を策定することである。障害からシステムを完璧に護ってくれる魔法のソリューションは存在しない。したがって、ITのプロはシステムを多層的な厚みで守る対策を確立しなければならない。
データセンターに冗長化を実装する
ITレジリエンシー・プランを確立する際の最初のステップは、システム停止によって起こりうる潜在的問題点の洗い出しと、その対応策としての冗長化の利用である。簡単な例を挙げると、企業はハードディスク障害からデータを守る手段としてディスクのミラーリングを日常的に使っている。同様に、あなたの会社ではノードレベル障害に対する防御としてフェールオーバー・クラスタリングを利用し、電源障害に対する防御にはバックアップの発電装置を利用しているかもしれない。
冗長化は重要ではあるが、それだけでは真のITレジリエンシーを実現することはできないだろう。データセンターの全てのコンポーネントがそれぞれに、冗長化されたコンポーネントによって保護されていたとしても、データセンター自身が障害点(ポイント・オブ・フェイラー)になることだって有りうる。
データセンター・レジリエンシーを確立する
企業は、たとえプライマリのデータセンターが機能停止、あるいは最悪センターの破壊が起こった後でも、なんとかして正常な運用を継続していかなければならない。ひとことで言えば、代替施設に運用を移転することができるか、ということだ。
これを実現するにはいくつかの方法がある。一般によく使われている方法は、遠距離クラスタリングである。この技術の背後にある基本的な考え方は、フェールオーバー・クラスターが距離を伸ばせるということと、クラスター・ノードが遠隔のデータセンターに配置できるということだ。データセンターそのものの障害が発生した場合、クラスター上で稼働している利用度の高いアプリケーションは自動的に遠隔の施設にフェールオーバーされる。
遠距離クラスタリングは成熟した技術だが、実装は意外に難しいと思われるかもしれない。要件はベンダーごとに異なるし、同じソフトウェアでもバージョンごとに変わる。さらに大変なのが、クラスターの距離とレイテンシの要件に対する計画を立てることだ。スプリットブレーン・シンドロームを回避しつつクラスター・ノードの定足数 (quorum)を調整し、クラスター・ノードとストレージを接続させなければならない。
データセンターのレジリエンシーを確保するために、時々使われることがあるもう一つの技術は、ストレージレプリケーションだ。Dell EMCやNetAppなどのベンダーがこの技術を提供している。とはいえ、レプリケーションは必ずストレージアプライアンス同士で行わなければならないか、というとそうでもない。MicrosoftやVMwareなどのハイパーバイザ・ベンダーはハードウェアに依存しない方式のレプリケーションを組み込んでいる。これにより、仮想マシン(VM)を代替のデータセンターまたはクラウドにレプリケートすることができるようになっている。
消失訂正符号(イレージャー・コーディング)を使って障害からデータを保護する方法もある。消失訂正符号の動きは、ストレージアレイのパリティと同じようなものだ。唯一の違いは、消失訂正符号ではデータが複数のデータセンター間または複数のクラウド間でストライプされる、という点だ。これにより、二つのはっきりしたメリットが生まれる。一つ目のメリットは、複数の離れた場所に複数のコピーを保存できるという点だ。管理者は通常冗長化するコピーの数または許容しうる障害数を設定する。
消失訂正符号のもう一つのメリットは、極秘データを安全に保管するのに役立つ点だ。企業がデータをパブリック・クラウドに保存すると決めたとき、消失訂正符号を使えば、ひとつのクラウドプロバイダーだけでは絶対そのデータの完全コピーを作れないような構造にすることができる。さらに、消失訂正符号は複数のクラウドにデータの断片を分散するため、一つあるいはそれ以上のクラウドが障害を起こしても、サービスの停止が起こらないように十分な冗長性を確保している。
VMホストやゲストクラスターはより高度な保護を提供してくれるか?
管理者の間でよく話題になるのが、VMホストやゲストクラスターを可用性確保のために使うべきか、という問題だ。
サーバー仮想化に先んじて、アプリケーションクラスター(Windowsフェールオーバー・クラスターにおいてクラスターの役割を与えられているアプリケーション)が、もともとアプリケーションの可用性を確保している。しかし今では、VMwareやMicrosoftなどの大手ハイパーバイザ・ベンダーは、仮想ホストレベルでクラスタリング機能を提供しており、ホストレベルの障害が発生した時には、仮想マシンは代替ホストにフェールオーバーできるようになっている。この技術によって、ほぼすべてのVMの可用性が非常に高くなった。
■ゲストクラスターがレガシークラスターを模倣することにより、アプリケーションの可用性は大きく向上する。これらフェールオーバークラスター・ノードは、専用の物理ハードウェアの替わりに仮想サーバー上で稼働する。
■ホストクラスターは、一見するとゲストクラスターの必要性を無くすかのように思える。ホストクラスターは、いかなるアプリケーション・レベルの仕組みからも独立して、クラスター内で稼働しているVMの高い可用性を提供しているからだ。とはいえ、仮想マシンのホストクラスターは、ホストレベルの障害からVMを護っているということを考慮に入れておくのが重要だ。ホストクラスターは、VMレベルの障害からアプリケーションを護ることに関しては一切何もしない。ゲストクラスターは、高い可用性の提供をVMだけでなくアプリケーションにまで拡張することによって、その保護のレベルを高める役割を提供している。
全てのアプリケーションがクラスタリングをサポートしているわけではないが、ゲストクラスタリングを使えるようにするのが、アプリケーションの可用性を高めるのに最善の方法だろう。物理サーバーの障害からVMを護るために、ハイパーバイザもホストクラスタリングでクラスター化しておくべきだ。
常時バックアップとインスタント・リカバリー
ここ数年、レプリケーションと常時可用性に対する注目度は上がってきているものの、依然としてバックアップ&リカバリーは極めて重要だ。レプリケーションは企業のリソースの冗長コピーを生成するが、冗長化によってポイント・イン・タイム・リカバリーの必要性が無くなるわけではない。例えば、ランサムウェアが企業のプライマリーデータセンターのデータを暗号化した場合、感染したデータは即座に全ての冗長化コピーへとレプリケートされてしまうだろう。障害から復旧する唯一の現実的方法は、障害が起きる以前の時点にデータをリストアすることだ。
バックアップ&リカバリーは何十年もの間、様々な形で存在してきたが、「常時ON」の環境はインスタント・リカバリー機能が付き継続的データ保護を求めている。
継続的データ保護は、一般に変更ブロックのトラッキングをベースに行われる。あるストレージブロックが生成または修正されると、そのブロックはバックアップの対象となる。以前は一般的だった、オフピークの時間帯に画一的にバックアップを行う方法に比べて、この方法では同期か非同期で継続的にデータがバックアップされる。
インスタント・リカバリーは、ひとつまたはそれ以上のVMをほとんど即時に復旧してくれる。従来型の復旧が終わるのを延々と待つ必要はない。インスタント・リカバリーのベースになっている考え方は、大半の企業は高度に仮想化され、バックアップ・ターゲットにVMの完全なコピーが存在している、というものだ。実際、企業においてリカバリー作業が必要になったとき、事前に設定しておいたマウントポイントからVMをマウントし、バックアップ・ターゲットから復旧することができる。これにより従来型の復旧がバックグラウンドで行われている間に、データへの即時アクセスが可能になる。
バックアップの整合性を保つために、バックアップから起動したVM内で発生した書き込み処理は、専用の仮想ハードディスクにリダイレクトされる。通常、これにはVMのプライマリ仮想ハードディスクのスナップショットについているチャイルド仮想ハードディスクが使われる。この方法で、VMのバックアップコピーが変更されてしまうことを防いでいる。リストアが完全に終了すると、インスタント・リカバリーが立ち上がってから発生した書き込み処理はVMの仮想ハードディスクにマージされる。この時点で、ユーザーセッションはバックアップVMから今回復旧されたプライマリVMへとリダイレクトされる。
Windowsサーバーのレジリエンシー
OSの新機能リストで往々にして見落とされがちだが、MicrosoftはWindows Server 2016を一時的なストレージ障害から復旧できるように設計している。ハイパーコンバージド基盤のデプロイメントを除いて、仮想ホストは滅多にVMをローカルストレージに保存しない。それゆえに、外部ストレージアレイとの接続がポイント・オブ・フェイラーになりうるのだ。
Windows Server 2012 R2およびそれ以前のWindows Server OSでは、Hyper-Vの仮想マシンで仮想ハードディスクの読み込みまたは書き込みの際障害が発生すると、そのマシンはクラッシュしていた。
しかしWindows Server 2016では、短時間のストレージ障害からシステムを保護する仕組みが加えられた。VMが突然仮想ハードディスクに読み込みまたは書き込みができなくなった場合、ハイパーバイザはVMスナップショットが生成されるのと同じような処理を行う。ハイパーバイザがVMを「フリーズ」してその時点の状態を保存するのだ。
ストレージが使えるようになった時、VMは再び「解凍」され、何事もなかったかのように処理が続行される。フリーズ中はエンドユーザーがVMにアクセスできなくなってしまうものの、以前であれば一時的障害によってクラッシュが発生していたところでも、これからはユーザーに気づかれずに処理が続行されることだろう。
今日、Veritas、Commvault、Veeamなどほとんどの大手バックアップ・ベンダーは、インスタント・リカバリーを提供している。ITのレジリエンシー・プランを立案する際、必要なのは常時可用性を提供するために作られた技術の実装だけにとどまらない。真のITレジリエンシーを実現する唯一の方法は、データセンター・フェールオーバーやインスタント・リカバリーなどあらゆるポイント・オブ・フェイラーへの対策を実装することによって、綿密な保護を実践していくことである。
著者略歴:Brien PoseyはIT業界数十年の経験をもつMicrosoft MVP。前職は全国展開する病院・医療施設のCIO。
Copyright 2000 - 2017, TechTarget. All Rights Reserved,
*この翻訳記事の翻訳著作権はJDSFが所有しています。 このページに掲載されている記事・写真・図表などの無断転載を禁じます。
![]()
 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム JEITA連載寄稿
JEITA連載寄稿 「Storage Magazine」
「Storage Magazine」
