
ビッグデータにはビッグストレージが必要
John Webster
Storage Magazine 2016年5月号より
エンタープライズ・ストレージベンダーとApacheコミュニティの貢献により、Hadoopの普及が進んでいる。
ストレージの議論には、データ増加についての話題がつきものだ。その際、暗黙の前提とされているのは、増加する解析アプリケーションに合わせて、企業はあらゆるデータをキャプチャーし保存したいと考えるだろう、ということだ。現在、多くの企業において「すべてのものを永久に保存する」というのが、保存されたデータ保管方法のデフォルトになっているため、多くの部門が数ペタバイトのデータを蓄積している。
読者はストレージのコモディティ化を思い浮かべるかもしれないが、実際にこれらすべてのデータを保存するにはお金がかかる。ならば、何故それをするのか。それば今日の経営者たちは、データ解析の進化によってデータの本来的価値に気付いているからだ。事実、データはお金になるのだ。経営者層が理解していることがもうひとつある。データを所有する価値が増加している一方で、IT基盤を所有する価値は下がっている、ということだ。
Hadoop分散ファイルシステム(HDFS)は、ビッグデータの問題に取り組むエンタープライズ・ストレージ・ユーザーが選ぶ「頼れるツール」へと急速に成長しつつある。本記事では、HDFSがいかにして一番人気のツールになったのかを詳細に見ていく。
全データをどこに置くべきか?
従来のエンタープライズストレージプラットフォーム、ディスクアレイとテープサイロは、あらゆるデータを保存するという業務には不向きだ。データセンター型アレイは将来見込まれるデータ量に対してあまりにも高価であり、テープは大容量を低コストで保存するのには向いているが、取り出しに時間がかかる。現在の企業が求めるレポジトリはしばしばビッグデータ・レイクと呼ばれ、これらのレポジトリで事例が最も多いのがHadoopだ。
GoogleとYahooのインターネット・データセンターで生まれたHadoopは、低コストの大規模ストレージ環境での高パフォーマンスの解析処理を提供するために設計された。
しかし、大規模インターネット・データセンターと企業のデータセンターとの間には、管理スタイル、支出の優先順位、コンプライアンス、リスク回避プロファイルなどに大きな隔たりがある。結果的に、Hadoop分散ファイルシステムにおいては、長期間存在するデータはもともと設計時に考慮されていなかった。前提とされたのは、データはバッチ処理ジョブのMapReduce用に分散クラスターにロードされ、次にアンロードされる。この処理がジョブの数だけ連続的に繰り返される、というものだ
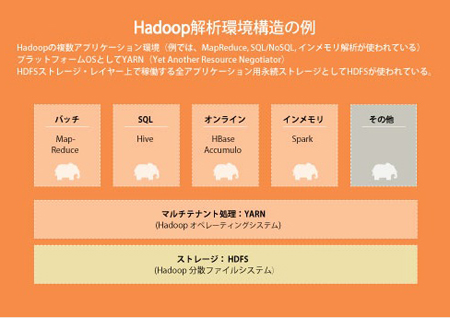
最近の企業は、MapReduceの連続ジョブを走らせることを望まないだけでなく、複数のアプリケーションを構築したいと思っている。一例としては、Hadoop分散ファイルシステム上に、オンライン・トランザクション処理(OLTP)で生成されたデータに対する解析を統合するようなシステムだ。複数のタイプの解析を行うために共通で使うストレージも必要である(Hadoopの複数アプリケーション環境がYARNとHadoop分散ファイルシステムによってサポートされている図1を参照)。さらに人気の高いアプリケーションとして、オンライン・トランザクション処理のApache HBaseや、リアルタイム解析のみならずデータストリーミング解析も行うApache SparkやStormがある。複数アプリによる解析の統合を行うためには、複数のユーザーグループが長期間にわたって使えるように、データは永続的に存在し、保護され、安全性を確保されていななければならない。
Hadoopストレージのギャップを埋める
現在のHadoop分散ファイルシステムは、永続データに対するするストレージ管理機能を備えており、Apacheオープンソース・コミュニティは、HDFSをよりエンタープライズ・データセンターの本番環境に準拠したものにすべく、長い時間をかけて改善を重ねてきた。
しかし、いくつかの重要な機能はいまだに欠落したままだ。そのため、HDFSストレージ・レイヤーが、Hadoop解析のプラットフォームのデータ保存基盤として、また増える一方のアプリケーションとユーザーに対して、本当に使えるものかどうかを判断するのは、管理者にとってはなかなかの難問だ。複数のApacheコミュニティ・プロジェクトが開発者の関心を集める一方で、ユーザーはしばしば本番環境で必要なHadoopストレージの機能を待たされる、という状況がある。現在、Hadoopストレージが埋めなければならない溝には
以下のようなものがある。
■非効率かつ貧弱なデータ保護機能とDR機能
HDFSはディスク障害、データ損失、接続障害、それに関連する機能障害からの復旧のために、データ取り込み(インジェスト)の際、データのコピーを複数(通常は3個)作成する。確かにこの処理によって、クラスターをディスク障害から守り、サービスを停止することなくパーツの交換が可能になるが、データ破損などのデータ損失の全パターンを救うことはできない。
最近の研究で、ノースカロライナ州立大学の研究者たちは、Hadoopはフォールト・トレランス機能を提供しているものの、「データの破損が起きた場合、Hadoopシステムの整合性、パフォーマンス、可用性には深刻な影響を受ける」ことを発見している。この処理はまた、非常に非効率的なストレージ媒体使用の元凶になっている。ユーザーが法令順守などの必要に迫られ、Hadoopクラスターに最大7年間データを保存したいと思った時、ここは非常に気になるところだ。Apache Hadoop開発コミュニティは今年後半、Hadoop分散ファイルシステムの新バージョンに、アクセス頻度の低い2次ティアに消失訂正符号を実装することを検討中だ。
HDFSはまた、Hadoopクラスター間でデータを同期レプリケーションすることができない。本番レベルのDR運用には同期レプリケーションのサポートが非常に重要であり、この部分も問題だ。非同期レプリケーションがサポートされてはいるが、ローカルとリモートのレプリカには常に不整合が発生する可能性がある。
図1
■計算リソースとストレージを分離できない
HDFSは計算リソースとストレージリソースをバインドし、計算処理とデータの距離を最小化することによって規模が拡張してもパフォーマンスが低下しないようにしている。しかしこの方法は、HDFSが永続的なストレージ環境として使われる時、管理者が当初思い描いていたのとは違う結果をもたらす。ストレージ容量をデータノードとして追加するには、管理者は必要・不要に関係なく計算リソースも追加しなければならない。ここで思い出してほしいのは、1TBの使用可能ストレージはコピーが作られた後、3TBに膨れ上がる。データの入出力処理は往々にして実際の問い合わせ処理より時間を要する。従来のデータウェアハウスに対する解析アプリケーション用Hadoopの使用上の大きな利点のひとつは、巨大な容量の非構造型データに対する問い合わせ能力だ。これはしばしば、実際のデータストアからビッグデータ・レイクにコピーすることによって実現されるが、データの量によっては非常に時間がかかりネットワークに負荷をかけることになる。本番環境におけるHadoopの観点からすれば、これは非常に重大な問題だ。これによって、データ不整合が起こり、アプリケーション・ユーザーは、自分が見ているのが整合性のある唯一の真のソースなのかどうか疑問を抱きかねない可能性があるからだ。
Hadoopのアドオンおよびストレージシステム代替製品
Apacheコミュニティは、しばしばHadoopの欠点を解決するためのアドオンプロジェクトを作っている。管理者は、クラスターの障害を再計算なしに復旧するためにRaft分散合意プロトコルやWANによって隔てられたクラスターの定期的同期のためにDistCp(分散コピー)ツールを使うことができる。フィード処理および管理システムツールFalconは、データのライフサイクルと管理機能を提供し、Rangerフレームワークはセキュリティ管理を一元化してくれる。これらのアドオンは、別々なものとしてインストールし、機能を学習し、管理しなければならない。また、個々のアドオンは、独自のライフサイクルを持っており、それぞれ履歴を管理し、更新を行う必要がある。
これらの問題を解決するために最近管理者の間で増えているのが、データセンター級のストレージをHadoopと統合する方法だ。データ保護、整合性、セキュリティ、データガバナンスの機能要件が組み込まれたストレージシステムとHadoopを統合するのだ。「Hadoop対応済み」のストレージ製品としては、EMC Isilon 、EMC Elastic Cloud Storage (ECS)、日立Hyper Scale-Out Platform、IBM Spectrum Scale、NetApp Open Solution for Hadoopなどがある。これらの代替製品が持つ潜在的な価値を理解するために、外部ベンダーによるHadoopストレージ製品のなかから2製品を見てみよう。
EMC Elastic Cloud Storage
ECSは出荷前に予め設定を済ませたハードウェア/ソフトウェアアプライアンスか、汎用サーバーのスケールアウト・ラックにインストール可能なソフトウェアとして販売されている。HDFSやNFS V3ファイルサービスの他にオブジェクトストレージ・サービスもサポートしている。オブジェクトへのアクセスは、Amazon Simple Storage Service (S3)、Swift、OpenStack Keystone V3、EMC Atmosインターフェースを介して行われる。
ECSはHadoopをファイルシステムとしてよりもむしろプロトコルとして利用する。使用に際しては、Hadoopクラスターレベルへのコードのインストールが必要で、ECSデータサービスは、HadoopクラスターノードがHadoop互換のファイルシステムを使って非構造型データへアクセスできるようにする。この製品は、ECSノードに組み込まれた半導体ドライブ、ハードディスクとのハイブリッド・ドライブ両方をサポートし、ユーザーの機器構成にもよるが、ラック1台あたり最大3.8PBまでの拡張が可能だ。データとストレージの管理機能として、スナップショット、ジャーナリング、バージョニングなどがついている。また、データ保護のために消失訂正符号処理(イレイジャーコーディング)が実装されている。3つのデータのコピーを管理するためのインデックスとメタデータ以外、ECSの全データは、消失訂正符号処理がなされている。
その他、エンタープライズの本番環境レベルのHadoopがもつ価値の高い機能としては以下のようなものがある:
■大小ファイルの書き込みパフォーマンスが一定
小さなファイルの書き込みは、ファイルを集約してから一回の操作で行われる。一方、大きなファイルの書き込みは複数のノードから並行に行われる。
■複数サイト・アクセスと3拠点サポート
ECSでは、複数サイトクラスターの中のどのECSサイトからでもデータへの即時アクセスが可能だ。データは強固な整合性を保っており、データがどこにあるか、またインデックスが全ロケーションにまたがって同期しているとしても、アプリケーションには最新のバージョンが提供される。ECSはまた、非同期レプリケーションの他に、プライマリ、リモート、セカンダリ間での単一クラスターもサポートしている。
■法令順守
ECSでは、管理者が時間に基づいたデータ保管ポリシーを設定できるようになっている。SEC Rule 17a-4のような規則順守もサポートされている。また、EMC Centera CE+ のロックダウン機能、削除権限機能もついている。
■検索
ユーザーが定義したメタデータと、システムレベルのメタデータ間の検索を実行できる。ユーザーが作ったインターフェースで、キーと値のペアを使ったインデックス形式の検索ができる。
■暗号化
インラインの保持データの暗号化は、ECSが生成するキーによって自動的に管理され、システム内に保持される。
IBM Spectrum Scale
IBM Spectrum Scaleは、高い拡張性(数PBクラス)と高いパフォーマンスを持つストレージ製品で、そのままHadoopと統合が可能だ(クラスターレベルのコードは不要)。この製品は統合ストレージ環境を実装する。これは、単一のグローバル名前空間のもとで、ファイルとオブジェクト・ベースのデータストレージが両方サポートされる、ということだ。
データ保護とセキュリティに関して、Spectrum Scaleはファイルシステムまたはファイルセットレベルのスナップショットを提供し、バックアップは、外部ストレージターゲット(バックアップ・アプライアンスおよび/またはテープ)に行われる。ストレージ・ベースのセキュリティ機能には、保存データの暗号化、データの完全消去、さらに認証のためにLDAP/ADが入っている。
LAN、MAN、WAN間の同期、非同期データレプリケーションは、トランザクション整合性を保ちながら行われる。
Spectrum Scaleは、高パフォーマンス用半導体ストレージと安価で数テラバイトの容量の機械型ディスク間を、ポリシーに基づいて自動的にデータを移動させる、ストレージ・ティアリング・システムをサポートしている。テープをアーカイブ・ストレージ・ティアとして追加可能だ。ポリシーに基づいたファイル単位のデータ圧縮を実装することもできる。これにより、ストレージ効率を約2倍改善し、Hadoopクラスターノードへの処理負荷の軽減が実現される。
さらに、メインフレーム・ユーザーのために、Spectrum ScaleはIBM zシステムと統合が可能になっている。Hadoopとの連携の際、IBMzシステムはリモート・データアイランドとしての役割を持つ。
姿を現したSpark
Apache Sparkは、Hadoopより高速にMapReduceアプリケーションを稼働させるビッグデータ解析用プラットフォームだ。Hadoopと同様、ストリーミングデータ解析も行うマルチアプリケーション・プラットフォームでもある。Sparkは効率の良いコードベースとインメモリ処理アーキテクチャーによって、汎用のハードウェアとオープンソースのコードを利用していながらも、高いパフォーマンスを実現する。Hadoopと違い、Sparkは独自の永続データストレージ層を持たないが、それゆえに、もっとも一般的なSparkの実装はHDFSを使ったHadoopクラスター上になっている。
Sparkが伸びている理由は、ストリーム処理とリアルタイム解析への関心の高まりからだ。再度言うが、Hadoop分散ファイルシステムはもともとストリーミング解析アプリケーションをサポートする永続データストアの機能を持っていなかった。SparkはHadoopでのストレージ・ティアリングのパフォーマンスをより魅力あるものにし、Hadoopとエンタープライズストレージの統合を検討させるきっかけになっている。
著者略歴:John WebsterはEvaluator Groupのシニア・パートナー兼アナリスト。
![]()
 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム JEITA連載寄稿
JEITA連載寄稿 「Storage Magazine」
「Storage Magazine」
