
旧世代のデータ保護を消し去る
Storage Magazine 2015年7月号より

RAIDとバックアップは、大容量システムおよびデータ増加と日々格闘している。消失訂正符号は、何故RAIDに替わりうる技術といえるのだろう?
RAIDが登場して約30年。急激なデータ量増加の中で、技術的な限界が見え始めている。ここに登場してきたのが消失訂正符号だ。RAIDの抱える問題を全て解決してくれるわけではないが、この新しい技術について見てみよう。
訳註:*今回の翻訳ではこの段落と「RAID入門」「RAID補語と復旧」の章を要約しています。
RAID入門
RAIDに限界が来ていることを理解するためにはまず、RAIDの仕組みを知る必要がある。RAIDは復旧に重点を置き、データを冗長化させることでデータ保護を実現する。この際、一定のストレージ容量が犠牲になる。今最も多く使われているRAID 5 とRAID 6でも、このことは変わらない。例えば、RAID 5で3+1のディスク構成の場合、冗長化データのために全容量の33%が使われる。
大容量化のために、巨大なRAIDを組める(最大28ドライブ)製品もあるが、ドライブを増やすと故障の確率も増える。さらに、復旧には全ドライブを読み込む必要があり、I/Oパフォーマンスが大幅に下がる。
この問題を緩和するために、複数のRAIDグループを跨いでディスクプールボリュームを構成するベンダーもいるが、冗長化に使用容量を差し引かれる弱点は残る。さらに、このタイプの構成ではパフォーマンスを上げるためにストライピングを行っているので、ひとつのRAIDグループでディスク二重障害が起こると全ボリュームに影響が及ぶ。
RAID保護と復旧
データがRAID5グループに書き込まれるとき、データストライプが作られる。データストライプには、データとパリティが入っている。パリティの計算はXOR(排他的論理和)に基づいて行われる。パリティが使われるのは障害が発生したときのみである。
ディスクの障害が発生したとき、パリティをもとにRAIDの再構築(リビルド)が行われる。
ドライブの容量が小さかった頃は、たいしたオーバーヘッドもなしに処理が終わっていたが、ドライブの容量が増えるにつれて再構築の時間がRAIDというデータ保護技術のアキレス腱になっていく。10TBドライブでRAIDが構成されるようになると、再構築には数ヶ月かかる、という話も出ている。
RAIDが再構築されている間、データが危険にさらされる、ということが無ければ再構築時間のことはそれほど問題にならなかったかもしれない。再構築中に同じRAIDグループでディスク障害が起こると、データ損失あるいは手作業による復旧をしなければならないからだ。
この問題の緩和のため、RAID6が作られた。これによりドライブ2台までの障害は救えるようになったが、容量とパフォーマンスの問題は残したままだ。ドライブ3台障害に耐えられるRAIDの話はあるが、現在のところ製品は出ていない。
最後に、考えなければならないのが回復不能の読み取りエラー(Unrecoverable
Read Error (URE))だ。UREはまれにしか起こらない(12.5TB分の読み込みに1回の発生率)といわれているが、ドライブの大容量化が進むにつれて、障害が起こる可能性も増えている。もし再構築の最中にUREが起こったらデータの復旧は不可能だ。
数千のドライブをもつ大規模なシステムでは、このような障害が起こる可能性は高くなってくる。
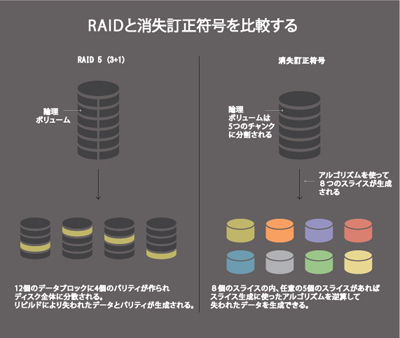
消失訂正符号によるデータ保護の仕組み
RAIDによるデータ保護は、オブジェクトストアに見られるような、非常に大規模なデータおよびディスクドライブには、明らかに不向きだ。この代替として、RAIDシステムでの拡張時の問題がないように、消失訂正符号をデータ保護手法のひとつとして実装する方向にベンダーは動き始めた。消失訂正符号(前方エラー訂正と呼ばれることもある)は、データ保護方法として冗長データを作成してそれを使うという点ではRAIDと同様の動きをする。
消失訂正符号はまず、元となるデータを「チャンク」と呼ばれる塊に分ける。次に、これらのチャンクに対して数学の関数が適用され、「スライス」あるいは「シャーズ(かけら)」が作られる。一例をあげると、消失訂正符号システムは8つのチャンクを取り込み、10個のスライスを生成する。このなかの8個のスライスがあれば、データの復旧ができる。この例では、消失訂正符号の使用によるオーバーヘッドは25%(8個にたいする2個)だが、このシステムはスライス2個が失われても大丈夫だ。このことは、スライスが10台のドライブに分散して保存されていれば、ディスクの二重障害にも耐えられる、ということを意味する。
また、消失訂正符号は生成するスライス数、復旧に必要になるスライス数を簡単に変えることができるという利点を持っている。そのため、沢山のデータ保護スキームを実装でき、同じ物理ディスクのグループに複数のスキームを実装することだって可能だ。さらにRAIDと違うのは、消失訂正符号はデータ量とドライブ数が増えるほど、効率と復元力を増すところだ。データを同じパーセンテージのオーバーヘッドでより多くのドライブに分散させるということは、より多くのドライブで障害が起きても、消失訂正符号により復旧が可能だということを意味する。さらに、元データのどんな断片でもチャンクの沢山の組み合わせを使って再生できるので、回復不能の読み取りエラーの問題も緩和される。
とはいうものの、この復元力の利点を享受するにはお金がかかる。消失訂正符号を実行する際に使われる数学の関数は、これまでRAIDで使われてきたXORよりも計算が複雑で、CPU負荷の増大ひいてはホストのレイテンシ増大へとつながる。さらに、リードのI/Oリクエストに応えるためには、別の数学関数を使って最小限のスライスのサブセットから元データを再構成しなければならない。ちなみにRAIDでは、このリクエストに対しては単純にディスクを読み込むだけでよい。同じ理屈で、データの更新に関しても、符号化されたデータを構成する全てのスライス・セットを読み込み、改めて消失訂正符号化処理を行い、データをディスクに書き戻すという一連の作業が必要になる。
このようなオーバーヘッドがあるため、消失訂正符号がなぜ最初にオブジェクトストアに適用されたのかを理解するのは簡単だ。オブジェクトは通常変更がなく、データそのものが更新されるよりは新しいバージョンとして追記されるのが一般的だからだ。
レプリケーション vs. 消失訂正符号
消失訂正符号が際立った長所を発揮する領域が、災害復旧用データ保護である。RAIDシステムは単一のストレージアレイ内のデータを保護する。そのため、ユーザーはアレイの障害やサイトごとの障害に備えてリモートレプリケーションに頼らざるをえない。レプリケーションは、二つの同一のデータセットを必要とする高価なソリューションである。しかも、通常片側のデータセットは滅多に(ことによると永久に)使われることがないのだ。消失訂正符号であれば、スライスは地理的に広範囲に分散でき、単一サイトやアプライアンスの損失を軽減するために使用できる。
例えば、データアクセスのために16スライス中12スライスを必要とする消失訂正符号の仕組みを想像して欲しい。これら16スライスは、4つのデータセンターに分散させることで、ひとつのデータセンターがなくなっても情報の損失を回避することができる。まったくディスク容量を追加しなくても、ここまでのレベルの復元力が実現できるのだ。ただし、パフォーマンスは最低でも12スライスの読み込みがベースになるため、これがサイト間のレイテンシの要因となりうることを頭に入れておくことが大事だ。
さて、消失訂正符号はバックアップの終焉を意味するのだろうか?データの更新が小さいブロックサイズ(通常4KBから8KB)単位で行われる従来のブロックベースのデータにとって、消失訂正符号はそのアルゴリズムの実装にかかるオーバーヘッドが大きく、実用に適さない。多くのベンダーが、小さいオブジェクトデータを扱う際、自社のオブジェクトストアにRAIDによるデータ保護を実装しているのを見かけるのは、この理由によるものだ。このデータは、いまだにバックアップが必要だ。
とはいえ、大きなオブジェクト(大半の非構造型データやファイルはこれにあたる)にとって、消失訂正符号は復元力と拡張性の高いデータ保護の仕組みを提供してくれる。(損壊や損失からデータを保護するために)バージョン管理機能とともに実装すれば、多くの場合バックアップの必要はなくなるだろう。
消失訂正符号がRAIDシステムと並存する形で共有ストレージアレイのデータ保護手法として徐々に導入されていき、これからはユーザーポリシーに基づいてシステムが、自動的にどちらかのデータ保護手法を選択するようになりそうだ。RAIDは無くならないが、将来のストレージシステムではデータ保護手法のひとつになっていくだろう。
著者略歴:Chris Evansは独立系コンサルタント兼Langton Blueの設立メンバー。
![]()
Copyright 2000 - 2015, TechTarget. All Rights Reserved,
*この翻訳記事の翻訳著作権はJDSFが所有しています。
このページに掲載されている記事・写真・図表などの無断転載を禁じます。
 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム JEITA連載寄稿
JEITA連載寄稿 「Storage Magazine」
「Storage Magazine」
