
メタデータで賢くなるストレージ
Storage Magazine 2015年5月号より
オブジェクトストアとメタデータのおかげでストレージシステムは賢くなり、スケールアウト・ストレージシステムの知能向上に貢献している。
非常に長い間、ストレージアレイの目的は、ただひとつの単純な目的を遂行することだった。I/O要求をできるだけすばやく終わらせ、要求元のホストに応答を返すことだ。様々な理由からこのことが主たる目的になったことは、とくに驚くような話はない。
第一に、ハードディスクは低速なデバイスだった(今でもそうだが)のに比べ、CPUの速度ははるかに速い。第二に、データは一般的にブロックとして、どこにでもあるLUNやボリュームの中に保存される。ストレージアレイは、ブロック内のコンテンツがどんなものなのか、まったく分からなかった。そもそも、データパスやデータフローを最適化する(QoSのような機能を実装する)機能がついていなかったのだ。
ストレージシステムが進化するにつれて、アレイはコンテンツを把握するようになった。最初はNASアプライアンスがこの機能を導入し、後にオブジェクト・ストレージシステムがこの機能を備えるようになった。NASもオブジェクトストアも、保持しているデータを表すのに役立つ追加情報を保存する機能を備えている。この追加情報が、メタデータ、別な言葉で言えば、データについてのデータだ。NASの場合、このデータはファイルシステムに保存され、NFSまたはSMBプロトコルを使って接続しているホストに提供される。メタデータには、ファイル名、書き込み日付/時刻、ファイルサイズ、アクセス権限などもっとも基本的な情報が入っている。しかし、パフォーマンスや可用性要件など、さらに拡張した追加情報をメタデータに入れることも可能だ。
オブジェクト・ストレージ
オブジェクト型システムでは、情報はファイルシステムの階層には保存されず、データがバイナリ・オブジェクトとして表される「フラットな名前空間」に保存され、オブジェクトIDで参照される。既存のファイル、メディアデータ(オーディオ/動画)、衛星テレメトリー(遠隔計測)データや地震データなど複雑なデータも含む、あらゆるタイプの情報がオブジェクトになれる。オブジェクトIDは、次の段階ではデータを戻すときの参照情報になる。将来は、(例えば)ひとつひとつのオブジェクトがLUNの中のブロックを表すことで、ブロック型デバイスを管理するようなオブジェクトストアが使えそうだ。
オブジェクトストアは各オブジェクトにメタデータを保存する機能を備えている。これは一般的にはキー/バリュー・ペアと呼ばれるフォーマットで行われる。「キー」はデータのタイプを表し(例:オブジェクト所有者)、一方「バリュー」はそのオブジェクトに関連している特定のデータ(例:ユーザー名、部課など)である。
これまで、オブジェクトストアはアクセス頻度の少ないデータの大規模レポジトリとして使われてきた。これは、オブジェクトストアにデータを保存したり取り出したりするには、オブジェクト全体にアクセスする必要があり、オブジェクトが巨大な場合、この処理に比較的長い時間を取られてしまうからだ(いくつかの製品ではオブジェクトの一部だけにアクセスして保存、取出しができるようになっている)。
データ保護手段として消失訂正符号などを使っていたりしても、オブジェクトの保存・取り出しは遅くなる。物理的に分散した構成では特にこの傾向が顕著だ。データのスライスが使用可能なハードウェア上に分散されている場合、データの取り出し速度は最も低速のノード/サーバーに合わせられてしまう。
オブジェクト・ストレージは、大企業が直面する最も一般的な問題を解決する技術として人気が出てきた。データ増加管理の問題である。ブロック型ストレージシステムは急速に増加するデータ用には設計されていない。非構造型データや、最近では機器が生成するデータがこれにあたる。それに対して、オブジェクト・ストレージは(単純に巨大なバイナリ・オブジェクトを保存することにより)抽象データを管理することができ大量のメタデータを個々のオブジェクトと関連付けできるため、このようなタイプのデータに最適だ。
インテリジェント・ストレージシステム
以上一通り状況を説明したが、オブジェクトストアとメタデータを使ってどのようにインテリジェント・ストレージシステムを作っていけるだろうか?
拡張性:
オブジェクトストアは、単一システム内で数ペタバイト単位までの拡張が可能だ。通常、このクラスの容量になると、最も高価なハイエンド・ストレージアレイ、スケールアウトNASシステム、テープライブラリーでないとシステムを構築できない。ところが、オブジェクトストアの急増する容量にたいするアプローチはもっと柔軟だ。システム構成にノード(つまりサーバー)を追加するだけで良いのだ。しかも多くの場合、ノードに使われるのは汎用のハードウェアだ。スケールアウト的に容量を増やすこの方式は、信頼性増加につながり、一体型あるいはシングルインスタンスのブロック型ストレージを多数配置する方式に比べ、配置の自由度と復元力が高い。オブジェクトストア内のメタデータはデータと共に拡張する。メタデータは、データそのものの中に埋め込まれるか、基盤のなかの専用部分で管理される。
オブジェクトストアには、ポリシー設定に基づいて複数のバージョンのオブジェクトを保持する機能がある。例えば、ひとつのシステム内で一定期間10個のオブジェクトのコピーを保持できる。オブジェクト・バージョン保持機能によって、スナップショットや継続的データ保護のようなデータ復旧機能を実装することが可能だ。
伸展性:
オブジェクト型システムは、根本のところは比較的単純にできている。ひたすら、オブジェクトとオブジェクト・メタデータを保存しているのだ。しかし、オブジェクトストアの情報を保持するメタデータを使うことにより、一定のインテリジェンスを持ってオブジェクトに対し必要な処理と管理を行う機能を備えることができる。例えば、各オブジェクトにストレージ・ティアのレベルを紐付けて、オブジェクトの年齢が一定の時間を経過したらより安価なストレージに移行したり、特定のファイルのユーザー・アクセスや更新状況を追跡したり、といった使い方をオブジェクトストアでできるかも知れない。
データに属性を割り当てる機能があるということは、ストレージ管理者の介在なしに自動でオブジェクトストアへ適切な処理を取れることを意味する。これは、データ保護、可用性、レジレンシーなどのサービスレベル属性を割り当てるためにポリシーを設定して実行される。ポリシーによって処理を自動化する機能は、高いレベルの拡張性を実現する上でのキーとなる。規模が巨大になってくると、一般的に人間では管理しきれなくなってくるからだ。
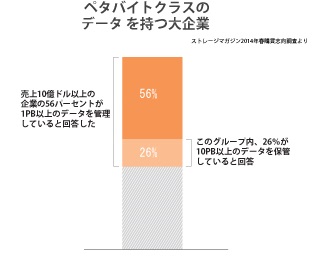
オブジェクトストアとメタデータは、今日二つのまったく別な使われ方をされている。一番目の使い方は、単純にオブジェクトデータを保存するためにだけオブジェクトストアを使う方法だ。多くの場合、これらのオブジェクトストアは、ゲートウェイあるいは非オブジェクト・プロトコルが使用できる追加機能によって補完されている。Scalityのようなベンダーは、最初から自社のソフトウェアにこのプロトコル対応機能をつけており、データコンテンツの分析機能ができるようになっている。
さらに面白いのが二番目の使い方だ。ここでは、ストレージプラットフォーム内でオブジェクト・ストレージインターフェースを明示的に意識することなくデータを保存する方法として、オブジェクトとメタデータ技術が使われる。今日、多くのストレージベンダーがこのタイプのシステムを販売している。
インテリジェント・ストレージベンダー
Coho Data社はSDN(ソフトウェア定義のネットワーク)とオブジェクトストアを組み合わせてNFSプロトコルに対応したスケールアウトのストレージプラットフォームを提供する製品を開発した。このシステムは、基盤上の負荷分散とデータ配置を管理する冗長化イーサネットスイッチ群と接続した、多数のMicroArrays(小さいサーバー)から構成されている。Coho社の製品はハイパフォーマンス環境や、特にサーバーおよびデスクトップ仮想化環境用に設計されている。
Data Gravity社は、Discoveryシリーズアプライアンスによってファイルやブロック型コンテンツを書き込み、インジェスト(データの取り込み)してこれらのデータ解析を行う製品を開発した。アーキテクチャーはデュアルコントローラーをベースにしており、片方のコントローラーが実際にデータを処理し(プライマリー・ノード)、もう一方がデータ管理や分析を行う(インテリジェント・ノード)。Data Gravity社の設計では、アクティブ/パッシブ型のデュアルコントローラー・アーキテクチャーでは、パッシブのコントローラーは一般的に不活発で分析業務に使用できる、というのが前提になっている。Data Gravity社は、Discoveryプラットフォームは400種類の異なるファイルやデータタイプを識別したり分析したりすることができる、と言う。
Exablox社は、2年前から市場にOneBloxという製品を供給してきた。この製品は下層アーキテクチャーとしてオブジェクトストアを使って、スケールアウトのNAS機能(SMBとCIFSに対応)を提供している。ユーザーはアプライアンスを購入するが、ディスクストレージにはユーザーが持っているものを使う。この製品は、あらゆる(最新の6TBタイプを含む)SAS/SATAドライブを組み込むことができる。可変長ブロック重複排除、CDP(継続的データ保護)、サイズが不揃いのディスクを使用する機能などは、ファイルを細かく分割したデータをオブジェクトにすることによって実現される。オブジェクトは次に接続されたデバイスのストレージ「リング」に分散される。例えば、CDPは複数のバージョンの更新をオブジェクトとして保持することにより簡単に実装できる。これは、オブジェクトストアの標準機能である。現在、OneBloxシステムは7ノードまで拡張でき、ひとつのノードあたり48TBの物理容量を持つことができる。

Primary Data社は2014年11月にステルスモードをやめて出てきたばかりの新興ベンダーだ。同社は、pNFS(パラレルNFS)をベースにした製品を作っているという噂があったイスラエルの新興企業、Tonian Systemsが開発した技術を買収している。Primary Data社のストレージは、データハイパーバイザとして動作するが、データ・トラフィックの中間に常駐するわけではない。代わりに、データプレーンと管理プレーンを切り離す。これには、「データディレクター」という可用性の高いクラスターが使われる。ハードウェアレベルのデータの物理的位置情報はそこに保存される。プレーンを分けることにより、全データが中央のアプライアンスを通過して発生するオーバーヘッドが無くなり、従来のインライン製品より遥かに大きな拡張性を実現している。とはいえ、この製品のマイナス面は各アクセスデータにドライバーソフトをインストールする必要があることだ。ここで買収した技術pNFSが必要になると思われる。メタデータ・ディレクトリーは、パフォーマンスと可用性の必要度に合わせて、データを基盤上の最適の場所に移動する機能を持っている。
Qumulo社も、「世界初データ・アウェア・スケールアウトNAS」と称するプラットフォームを引っさげて、ステルスモードから出てきた会社だ。この会社は、EMCに買収されたIsilonの数名の創立メンバーによって設立された。このチームの前回の経験から想像すると、Qumulo Coreとして知られる彼らの主要製品には、Isilonと同様の機能がいくつか入ってくるだろうと思われる。このCoreシステムはアプライアンスセットとして提供される(4ノードから1000ノードまでの拡張が可能)。しかし、この製品の目玉はソフトウェア、とくにデータ解析で、解析はリアルタイムで提供されるとのことだ。
他の多くの製品と同じように、Qumulo社もQSFS(Qumulo Scalable File System)と呼ばれる独自のファイルシステムを持っている。QSFSは、ストレージレイヤーの最上位に常駐する。独自のファイルシステムを持つことにより、Qumuloのソフトウェアはファイルレベルでデータを収集と解析が可能になり、従来のスケールアウトNASシステムが実現するよりも的確な判断と実用的な情報を提供できるようになった。(完)
著者略歴:Chris Evansは独立系コンサルタント兼Langton Blueの設立メンバー。

Copyright 2000 - 2015, TechTarget. All Rights Reserved,
*この翻訳記事の翻訳著作権はJDSFが所有しています。
このページに掲載されている記事・写真・図表などの無断転載を禁じます。
 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム JEITA連載寄稿
JEITA連載寄稿 「Storage Magazine」
「Storage Magazine」
