
De-dupe機能概要
|
データ・デデュプリケーション(Data Deduplication)の deduplication は「複製」を表す duplication の前に「隔離」とか「除去」を現すde が付いた言葉です。同じように de が付く言葉では debug が(業界的に)有名です。"deduplication"でひとつの単語として成立しているのですが、de を意識して "de-duplication" という記述が用いられることも多く見られます。 日本語での標記は「重複除去」や「重複除外」などいくつかの使われ方がされています。 一度データを溜め込んで処理する方式の製品では「重複除去」があっているし、溜め込む途中で処理する製品は「重複除外」があっているように思えますが、一般的に「重複排除」が浸透してきています。 JDSFでの記述は de を区別するとともに短縮して "De-dupe" 、日本語で「重複排除」を使用することにいたしました。 |
| De-dupe機能概念 | ||
|
||
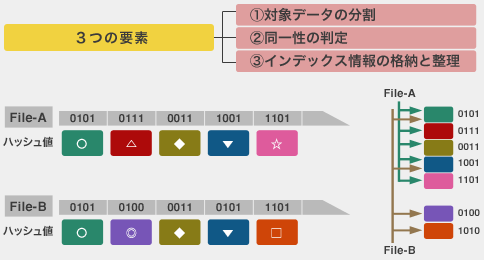
| 対象データの分割方式 | ||||||||||||
|
||||||||||||
| 同一性の判定方法 | ||||||||||
|
||||||||||
| インデックスの情報格納と管理 | ||||||||
|
||||||||
 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム 恋塚正隆の連載コラム
恋塚正隆の連載コラム JEITA連載寄稿
JEITA連載寄稿 「Storage Magazine」
「Storage Magazine」
